
Рядки та cимволи
Рядком ми будемо називати послідовність символів, таку як "hello, world" чи "albatross". У Swift рядки представлені типом String. Вміст рядка String можна отримати у кілька різних способів, у тому числі через колекцію значень типу Character.
У мові Swift, типи String та Character надають швидкий та сумісний з кодуванням Unicode спосіб працювати із текстами у вашому коді. Синтаксис створення рядків та маніпуляцій з ними є лаконічним, легким для читання, а синтаксис оголошення рядкових літералів є подібним до мови C. Для конкатенації, тобто поєднання рядків, достатньо просто поєднати дві рядкові змінні оператором +, а щоб керувати константністю/змінністю рядка, досить просто обрати між константою чи змінною, як, власне, і з будь-яким іншим значенням у Swift. Ви можете також вставляти в рядки константи, змінні, літерали чи вирази за допомогою механізму інтерполяції рядків. Це дозволяє легко створювати власні рядкові значення для зберігання тексту, виводу його на екран та друку.
Попри простоту синтаксису, тип String у Swift є швидкою та сучасною реалізацією рядка. Кожен рядок складається із незалежних від кодування символів Unicode, і надає підтримку доступу до цих символів у різних представленнях Unicode.
Примітка
Тип
Stringу Swift має міст із класомNSStringв модулі Foundation. Модуль Foundation розширює типStringметодами, визначеними вNSString. Це означає, що включивши модуль Foundation, ми можете користупитись методамиNSStringна значеннях типуStringбез приведення типів.За додатковою інформацією щодо використання типу
Stringіз модулями Foundation та Cocoa, дивіться розділ “Working with Cocoa Data Types” в книзі Using Swift with Cocoa and Objective-C (Swift 3.0.1)
Рядкові літерали
Рядкові літерали потрібні для того, щоб включати заздалегідь визначені значення String у ваш код. Рядковим літералом є фіксована послідовність тестових символів, оточена парою подвійних лапок ("").
You can include predefined String values within your code as string literals. A string literal is a fixed sequence of textual characters surrounded by a pair of double quotes ("").
Рядковий літерал можна використовувати як початкове значення для константи чи змінної:
let someString = "Some string literal value"
Слід помітити, що Swift визначає тип константи someString як String, бо вона ініціалізується за допомогою рядкового літерала.
Багаторядкові літерали
Якщо вам оголосити текстову константу або змінну, що охоплює декілька рядків, слід використовувати багаторядкові літерали: це послідовність символів, обмежена трійками подвійних лапок:
let quotation = """
The White Rabbit put on his spectacles. "Where shall I begin,
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on
till you come to the end; then stop."
"""
Багаторядковий літерал містить у собі кожен рядок тексту між лапками, що його відкривають, і лапками, що його закривають. Текст літералу починається з першого рядку після лапок, що його відкривають ("""), та закінчується на рядку, що передує лапкам, що його закривають. Це означає, що текст літералу не починається і не закінчується символом переносу рядка:
let singleLineString = "Ці рядки однакові."
let multilineString = """
Ці рядки однакові.
"""
Якщо ваш код містить символ переносу рядка всередині багаторядкового літералу, цей символ переносу рядка буде також міститись у текстовому значенні літерала. Якщо ви хочете використовувати символи переносу рядка для того, аби легше читати ваш код, але не хочете, щоб ці символи переносу рядка були частиною текстового значення літерала, слід писати бекслеш (\) наприкінці кожного з таких рядків:
let softWrappedQuotation = """
The White Rabbit put on his spectacles. "Where shall I begin, \
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on \
till you come to the end; then stop."
"""
Щоб текст багаторядкового літералу починався або закінчувався символом переносу рядка, слід відповідно розпочати або закінчити літерал порожнім рядком. Наприклад:
let lineBreaks = """
This string starts with a line break.
It also ends with a line break.
"""
Багаторядковий літерал може містити відступи, щоб відповідати коду довкола. Кількість пробілів перед трійкою лапок, що закриває літерал ("""), вказує компілятору Swift, скільки пробілів ігнорувати перед кожним з решти рядків літералу. Однак, якщо вказати кілька додаткових пробілів на початку якогось рядка, на додачу до кількості пробілів перед лапками, що закривають літерал, то ці додаткові пробіли будуть включені.

У прикладі вище, незважаючи на те, що весь багаторядковий літерал оголошено з відступом, перший і останній рядок його текстового значення не починається з жодних пробілів. Середній же рядок містить більше пробілів, аніж перед лапками, що закривають літерал, тому він починається з відступу довжиною у чорити пробіли.
Спеціальні символи в рядкових літералах
Рядкові літерали можуть включати наступні спеціальні символи:
- Екрановані спеціальні символи:
\0(нульовий символ),\\(зворотний слеш),\t(горизонтальний таб),\n(перенесення рядка),\r(повернення каретки),\"(подвійні лапки) та\'(одинарні лапки) - Довільний юнікодовий скаляр, записаний у формі
\u{n}, де n - це 1–8-цифове число в шістнадцятковому записі зі значенням, що відповідає дійсній кодовій позиції Юнікоду.
Код нижче показує чотири приклади спеціальних символів. Константа wiseWords містить пару екранованих подвійних лапок. Константи dollarSign, blackHeart, та sparklingHeart демонструють формат юнікодових скалярів:
let wiseWords = "\"Уява важливіша за знання\" - Ейнштейн"
// "Уява важливіша за знання" - Ейнштейн
let dollarSign = "\u{24}" // $, Unicode scalar U+0024
let blackHeart = "\u{2665}" // ♥, Unicode scalar U+2665
let sparklingHeart = "\u{1F496}" // 💖, Unicode scalar U+1F496
Оскільки багаторядкові літерали пишуться з трьома парами подвійних лапок замість лише однієї пари, то всередині їх можна використовувати символ лапок (") без екранування. Але для того, щоб включити текст """ до багаторядкового літералу, слід екранувати хоча б одну пару лапок. Наприклад:
let threeDoubleQuotationMarks = """
Екранування першої пари лапок \"""
Екранування всіх трьох пар лапок \"\"\"
"""
Розширені розділювачі рядків
Рядковий літерал можна розмістити поміж розширених розділювачів: таким чином можна включати до рядка спеціальні символи не викликаючи їх ефектів. Для цього потрібно розмістити свій рядок поміж лапок (") та оточити це символами решітки (#). Наприклад, якщо ми надрукуємо рядковий літерал #"Рядок 1\nРядок 2"# , то побачимо символ перенесення рядку \n замість друку літералу у два рядки.
Якщо ж потрібно, щоб деякі зі спеціальних символів у рядку діяли, слід використовувати символ або символи решітки (#) разом із бекслешем, що екранує спеціальний символ (\). При цьому кількість символів решітки при бекслеші має відповідати кількості символів решітки самого літерала. Наприклад, якщо ми маємо рядок #"Line 1\nLine 2"# і нам потрібно, щоб символ перенесення рядку ( \n) працював, слід натомість писати так: #"Line 1\#nLine 2"#. Аналогічно, у літералі ###"Line1\###nLine2"### перенесення рядку також відбувається.
Рядкові літерали, які створюються за допомогою розширених розділювачів рядків, можуть бути також і багаторядковими. Зокрема, можна використовувати розширені розділювачі для того, щоб включити текст """ в багаторядковий літерал, таким чином змінюючи поведінку таких літералів за замовчанням. Наприклад:
let threeMoreDoubleQuotationMarks = #"""
Ось ще одна трійка подвійних лапок: """
"""#
Ініціалізація порожнього рядка
Щоб створити порожній рядок, як початковий крок в побудові довшого рядка, можна або присвоїти порожній рядковий літерал змінній, або створити новий екземпляр String за допомогою синтаксису ініціалізації:
var emptyString = "" // порожній рядковий літерал
var anotherEmptyString = String() // синтаксис ініціалізації
// обидва рядки порожні, і дорівнюють одне одному
Щоб визначити, чи порожній рядок, слід перевірити Булеве значення властивості isEmpty:
if emptyString.isEmpty {
print("Nothing to see here")
}
// Друкує "Nothing to see here"
Змінюваність рядків
Щоб вказати, чи можна змінити (або мутувати) певне значення String, слід або присвоїти це значення змінній (тоді його можна буде змінити), або присвоїти це значення константі (тоді його не можна буде змінити):
You indicate whether a particular String can be modified (or mutated) by assigning it to a variable (in which case it can be modified), or to a constant (in which case it cannot be modified):
var variableString = "Horse"
variableString += " and carriage"
// змінна variableString тепер має значення "Horse and carriage"
let constantString = "Highlander"
constantString += " and another Highlander"
// це призведе до помилки часу компіляції - константний рядок не можна змінювати
Примітка
Даний підхід відрізняється від мутацій рядків в Objective-C та Cocoa, де ви обираєте між двома класами, (
NSStringтаNSMutableString), щоб вказати, чи можна змінювати рядок.
Рядки є Типами-значеннями
Тип String у Swift є типом-значенням. Якщо створити нове значення String, це значення String буде копіюватись при передаванні до функції чи методу, чи при присвоєнні змінній чи константі. В кожному випадку буде створюватись нова копія наявного значення String, і ця нова копія буде передаватись чи присвоюватись, а не оригінальна версія. Типи-значення детальніше описані в розділі Структури та Перечислення як Типи-значення.
Поведінка копіювання за замовчанням рядків у Swift гарантує, що коли функція чи метод передає вам значення String, саме ви володієте цим точним значенням String, незалежно від того, звідки воно прийшло. Ви можете бути впевнені в тому, що переданий вам рядок не буде змінено ніким окрім як вами самими.
За лаштунками, компілятор Swift оптимізовує використання рядків таким чином, що фактичне копіювання відбувається тільки тоді, коли це дійсно необхідно. Це означає, що ви завжди отримаєте чудову швидкодію при роботі з рядками як із типами-значеннями.
Робота із символами
Отримати доступ до окремих символів Character у рядку String можна ітеруючи його властивість characters за допомогою циклу for-in:
for character in "Собака!🐶".characters {
print(character)
}
// С
// о
// б
// а
// к
// а
// !
// 🐶
Цикл for-in детально описаний в підрозділі Цикл For-In.
Як варіант, можна створити окремий символ Character у вигляді константи чи змінної з односимвольного рядкового літерала, вказавши анотацію типу Character:
let exclamationMark: Character = "!"
Значення String можна сконструювати, передавши масив символів Character як аргумент його ініціалізатора:
let catCharacters: [Character] = ["К", "и", "ц", "я", "!", "🐱"]
let catString = String(catCharacters)
print(catString)
// Друкує "Киця!🐱"
Конкатенація рядків та символів
Значення String можна з’єднувати разом (або конкатенувати) за допомогою оператора додавання (+), при цьому буде створено новий рядок:
let string1 = "hello"
let string2 = " there"
var welcome = string1 + string2
// змінна welcome тепер дорівнює "hello there"
Ви можете також додавати значення String в кінець наявної змінної String за допомогою оператора додавання з присвоєнням (+=):
var instruction = "look over"
instruction += string2
// змінна instruction тепер дорівнює "look over there"
Ви можете додати символ Character до змінної String за допомогою методу append() типу String:
let exclamationMark: Character = "!"
welcome.append(exclamationMark)
// змінна welcome тепер дорівнює "hello there!"
Примітка
Ви не можете додати рядок
Stringчи символCharacterдо існуючої змінноїCharacter, бо значенняCharacterможуть містити лише один символ.
Інтерполяція рядків
Інтерполяція рядків є способом створити новий рядок String із комбінації констант, змінних, літералів та виразів, включаючи їх значення всередині рядкового літерала. Кожен елемент, що вставляється в рядковий літерал, має бути оточений парою дужок, перед якими йде зворотний слеш (\):
let multiplier = 3
let message = "\(multiplier) рази по 2.5 дорівнює \(Double(multiplier) * 2.5)"
// константа message дорівнює "3 рази по 2.5 дорівнюєи 7.5"
У прикладі вище, значення multiplier вставляється в рядковий літерал як \(multiplier). Цей заповнювач буде замінено фактичним значенням константи multiplier під час виконання інтерполяції рядку у ході створення даного рядка.
Значення multiplier є також частиною більшого виразу далі в рядку. Цей вираз обчислює значення Double(multiplier) * 2.5 і вставляє результат (7.5) в рядок. В цьому випадку, вираз записується як \(Double(multiplier) * 2.5) для включення в рядковий літерал.
Примітка
Вирази, котрі ви пишете всередині дужок при інтерполяції рядків, не можуть містити неекранованих зворотніх слешів (
\), символів зміни рядка (\n) чи символів повернення каретки (\r). Однак вони можуть містити інші рядкові літерали.
Юнікод
Юнікод - це міжнародний стандарт для кодування, представлення та обробки тексту в різних системах писемності. Він дозволяє вам представити практично будь-який символ з будь-якої мови у стандартизованій формі, зчитувати та виводити ці символи із будь-якого зовнішнього джерела в будь-яке інше зовнішнє джерело, такі як текстовий файл чи веб-сторінка. Типи String та Character у мові Swift є повністю сумісними із Юнікодом, про що й ітиме мова у даному підрозділі.
Юнікодові скаляри
За лаштунками, вбудований у Swift тип String будується із юнікодових скалярних значень. Юнікодовим скаляром є унікальне 21-бітне число для позначення символу чи модифікатора, як, наприклад, U+0061 для LATIN SMALL LETTER A ("a"), або U+1F425 для FRONT-FACING BABY CHICK ("🐥").
Примітка
Юнікодовим скаляром є будь-яка кодова позиція у проміжку від
U+0000доU+D7FFвключно, або відU+E000доU+10FFFFвключно. Юнікодові скаляри не включають кодові позиції сурогатних пар, котрі є кодовими позиціями у проміжку відU+D800доU+DFFFвключно.
Слід зазначити, що не всі 21-бітні юнікодові скаляри присвоєні символам: деякі скаляри зарезервовано для майбутнього використання. Скаляри, котрі були присвоєні символам, як правило також мають ім’я, як наприклад LATIN SMALL LETTER A та FRONT-FACING BABY CHICK у прикладах вище.
Розширені кластери графем
Кожен екземпляр типу Character у Swift представляє єдиний розширений кластер графем. Розширений кластер графем - це послідовність одного чи більше юнікодових скалярів, котрі при об’єднанні дають єдиний графічний символ.
Ось наприклад. Літера é може бути представлена як єдиний юнікодовий скаляр é (LATIN SMALL LETTER E WITH ACUTE, або U+00E9). Однак, ця ж літера також може бути представлена як пара скалярів: стандартна літера e (LATIN SMALL LETTER E, або U+0065), і слідом за нею скаляр COMBINING ACUTE ACCENT (U+0301). Скаляр COMBINING ACUTE ACCENT графічно застосовується до скаляра, що йому передує, перетворюючи e в é при рендерингу в системі рендерингу тексту, сумісної з Юнікодом.
В обох випадках, літера é представляється єдиним значенням Character, що представляє розширений кластер графем. В першому випадку, кластер містить єдиний скаляр, в другому випадку - це кластер із двох скалярів:
let eAcute: Character = "\u{E9}" // é
let combinedEAcute: Character = "\u{65}\u{301}" // e та слідом за нею ́
// eAcute дорівнює é, combinedEAcute дорівнює é
Розширені кластери графем є гнучким способом представити багато складних символів письма як єдине значення Character. Наприклад, склади Ханґиль із корейської абетки можуть бути представлені як у вигляді попередньо складеного єдиного юнікодового скаляру, так і у вигляді послідовності окремих юнікодових скалярів. Обидва представлення визначають одне й те ж саме значення Character у Swift:
let precomposed: Character = "\u{D55C}" // 한
let decomposed: Character = "\u{1112}\u{1161}\u{11AB}" // ᄒ, ᅡ, ᆫ
// precomposed дорівнює 한, decomposed дорівнює 한
Розширені кластери графем дозволяють знакам обведення (таким як COMBINING ENCLOSING CIRCLE, або U+20DD) обводити інші юнікодові скаляри всередині єдиного значення Character:
let enclosedEAcute: Character = "\u{E9}\u{20DD}"
// enclosedEAcute дорівнює é⃝
Юнікодові скаляри для символів індикації регіонів можуть поєднуватись у пари, щоб зібрати одне значення Character, як наприклад ця комбінація REGIONAL INDICATOR SYMBOL LETTER U (U+1F1FA) та REGIONAL INDICATOR SYMBOL LETTER A (U+1F1E6):
let regionalIndicatorForUA: Character = "\u{1F1FA}\u{1F1E6}"
// regionalIndicatorForUA дорівнює 🇺🇦
Кількість символів
Щоб отримати кількість символів Character у рядку, слід використовувати властивість count властивості characters рядка.
let unusualMenagerie = "Koala 🐨, Snail 🐌, Penguin 🐧, Dromedary 🐪"
print("unusualMenagerie містить \(unusualMenagerie.characters.count) символів")
// Друкує "unusualMenagerie містить 40 символів"
Варто зазначити, що використання розширених графемних кластерів для значень Character у Swift означає, що конкатенація та модифікація рядків не завжди впливає на кількість символів у рядку.
Наприклад, якщо ініціалізувати новий рядок чотирьохсимвольним словом cafe, а потім приєднати до його кінця символ COMBINING ACUTE ACCENT (U+0301), результівний рядок буде все ще мати кількість символів 4, із четвертим символом é, замість e:
var word = "cafe"
print("кількість символів у \(word) дорівнює \(word.characters.count)")
// Друкує "кількість символів у cafe дорівнює 4"
word += "\u{301}" // COMBINING ACUTE ACCENT, U+0301
print("кількість символів у \(word) дорівнює \(word.characters.count)")
// Друкує "кількість символів у café дорівнює 4"
Примітка
Розширені графемні кластери можуть складатись із одного чи більше юнікодових скалярів. Це означає що різні символи - і різні представлення одного й того ж самого символа - можуть потребувати різної кількості пам’яті для зберігання. Через це, різні символи у Swift займають різну кількість пам’яті всередині представлення рядка. Як результат, кількість символів у рядку не може бути обчисленою без ітерування самого рядка для визначення меж графемних кластерів. Якщо ви працюєти із досить довгими рядками, майте на увазі, що властивість
charactersповинна проітерувати всі юнікодові скаляри у всьому рядку, щоб визначити символи для даного рядка.Кількість символів, якуи поверне властивість
charactersне завжди дорівнює властивостіlengthв екземплярі класуNSString, що містить ті ж само символи. ДовжинаNSStringбазується на кількості 16-бітних кодових одиниць в представленні рядка UTF-16, а не кількістю юнікодових розширених графемних кластерів всередині рядка.
Доступ до елементів рядка і його модифікація
Маніпулювати рядком можна за допомогою його методів та властивостей, або за допомогою синтаксису індексації.
Індекси рядка
Кожен рядок String має асоційований тип індексу, String.Index, котрий відповідає позиції кожного символу Character в рядку.
Як зазначено вище, різні символи можуть вимагати різної кількості пам’яті для зберігання, тому для того, щоб визначити, який саме символ знаходиться за даною позицією, слід проітерувати кожен юнікодовий скаляр з початку чи з кінця цього рядка. З цієї причини, рядку у Swift не можуть мати цілочисельні індекси.
За допомогою властивості startIndex можна отримати позицію першого символу в рядку. Властивість endIndex є позицією після останнього символу в рядку. Як результат, властивість endIndex не є коректним аргументом для індексу рядка. Якщо рядок порожній, властивості startIndex та endIndex дорівнюють одна одній.
Щоб отримати індекси перед та після даного індексу, слід використовувати методи String index(before:) та index(after:) відповідно. Щоб отримати індекс трохи далі від даного, слід використовувати метод index(_:offsetBy:) замість того, щоб викликати один з попередніх методів кілька разів.
Щоб отримати символ рядка за даним індексом, слід використовувати синтаксис індексації ([]).
let greeting = "Guten Tag!"
greeting[greeting.startIndex]
// G
greeting[greeting.index(before: greeting.endIndex)]
// !
greeting[greeting.index(after: greeting.startIndex)]
// u
let index = greeting.index(greeting.startIndex, offsetBy: 7)
greeting[index]
// a
Спроби отримати індекс за межами діапазону символів рядка, чи звернутись до символу за межами рядка, призведе до помилки на етапі виконання.
greeting[greeting.endIndex] // Помилка
greeting.index(after: greeting.endIndex) // Помилка
Use the indices property of the characters property to access all of the indices of individual characters in a string.
for index in greeting.characters.indices {
print("\(greeting[index]) ", terminator: "")
}
// Надрукує "G u t e n T a g ! "
Примітка
Можна користуватись властивостями
startIndexтаendIndex, а також методамиindex(before:),index(after:), таindex(_:offsetBy:)на будь-якому типі, що підпорядковується протоколуCollection. Таким типом єString, як показано тут, так само такими є типи колекцій, такі якArray,Dictionary, таSet.
Вставка та видалення
Щоб вставити один символ в рядок за визначеним індексом, можна користуватись методом insert(_:at:), а щоб вставити вміст іншого рядка за визначеним індексом, можна скористатись методом insert(contentsOf:at:).
var welcome = "hello"
welcome.insert("!", at: welcome.endIndex)
// welcome тепер дорівнює "hello!"
welcome.insert(contentsOf:" there".characters, at: welcome.index(before: welcome.endIndex))
// welcome тепер дорівнює "hello there!"
Щоб видалити один символ із рядка за визначеним індексом, можна використати метод remove(at:), а щоб видалити підрядок за визначеним діапазоном, можна скористатись методом removeSubrange(_:):
welcome.remove(at: welcome.index(before: welcome.endIndex))
// welcome тепер дорівнює "hello there"
let range = welcome.index(welcome.endIndex, offsetBy: -6)..<welcome.endIndex
welcome.removeSubrange(range)
// welcome тепер дорівнює "hello"
Примітка
Методи
insert(_:at:),insert(contentsOf:at:),remove(at:), таremoveSubrange(_:)можна використовувати на будь-якому типі, що підпорядковується протоколуRangeReplaceableCollection. Це включаєString, як показано тут, так же як і типи колекцій, такі якArray,Dictionary, таSet.и
Порівняння рядків
Swift надає три способи порівнювати текстові значення: рівність рядків та символів, рівність префіксів та рівність суфіксів.
Рівність рядків та символів
Рівність рядків та символів перевіряється оператором “дорівнює” (==) та оператором “не дорівнює”, як показано в підрозділі Оператори порівняння:
let quotation = "We're a lot alike, you and I."
let sameQuotation = "We're a lot alike, you and I."
if quotation == sameQuotation {
print("Ці два рядки вважаються еквівалентними")
}
// Надрукує "Ці два рядки вважаються еквівалентними"
Два рядки String (або два символи Character) вважаються еквівалентними, якщо їх розширені кластери графем є канонічно еквівалентні. Розширені кластери графем є канонічно еквівалентними, якщо вони мають однакові лінгвістичні значення та вигляд, навіть якщо вони складаються із різних юнікодових скалярів за лаштунками.
Наприклад, символ, що складається зі скаляра LATIN SMALL LETTER E WITH ACUTE (U+00E9) є канонічно еквівалентним до символу, що складається зі скалярів LATIN SMALL LETTER E (U+0065) та COMBINING ACUTE ACCENT (U+0301). Обидва ці розширені графемні кластери представляють символ é, тому вони вважаються канонічно еквівалентними:
// "Voulez-vous un café?" використовуючи 'LATIN SMALL LETTER E WITH ACUTE'
let eAcuteQuestion = "Voulez-vous un caf\u{E9}?"
// "Voulez-vous un café?" використовуючи 'LATIN SMALL LETTER E' та 'COMBINING ACUTE ACCENT'
let combinedEAcuteQuestion = "Voulez-vous un caf\u{65}\u{301}?"
if eAcuteQuestion == combinedEAcuteQuestion {
print("Ці два рядки вважаються еквівалентними")
}
// Надрукує "Ці два рядки вважаються еквівалентними"
І навпаки, LATIN CAPITAL LETTER A (U+0041, або "A"), що використовується в англійській мові, не є еквівалентним до CYRILLIC CAPITAL LETTER A (U+0410, або "А"), що використовується в українській мові. Ці символи візуально схожі, але мають різне лінгвістичне значення:
let latinCapitalLetterA: Character = "\u{41}"
let cyrillicCapitalLetterA: Character = "\u{0410}"
if latinCapitalLetterA != cyrillicCapitalLetterA {
print("Ці два символи не є еквівалентними.")
}
// Надрукує "Ці два символи не є еквівалентними."
Примітка
Порівняння рядків та символів у Swift не враховує поточну локаль.
Рівність префіксів та суфіксів
Щоб дізнатись, чи має рядок певний префікс чи суфікс, використовуйте методи hasPrefix(_:) та hasSuffix(_:) відповідно, обидва з яких приймають єдиний аргумент типу String та повертають булеве значення.
У прикладах нижче розглядається масив рядків, що представляє локації сцен із перших двох актів шекспірівської Ромео і Джульєтта:
let romeoAndJuliet = [
"Act 1 Scene 1: Verona, A public place",
"Act 1 Scene 2: Capulet's mansion",
"Act 1 Scene 3: A room in Capulet's mansion",
"Act 1 Scene 4: A street outside Capulet's mansion",
"Act 1 Scene 5: The Great Hall in Capulet's mansion",
"Act 2 Scene 1: Outside Capulet's mansion",
"Act 2 Scene 2: Capulet's orchard",
"Act 2 Scene 3: Outside Friar Lawrence's cell",
"Act 2 Scene 4: A street in Verona",
"Act 2 Scene 5: Capulet's mansion",
"Act 2 Scene 6: Friar Lawrence's cell"
]
Можна використати метод hasPrefix(_:) з масивом romeoAndJuliet, щоб підрахувати кількість сцен у першому акті п’єси:
var act1SceneCount = 0
for scene in romeoAndJuliet {
if scene.hasPrefix("Act 1 ") {
act1SceneCount += 1
}
}
print("У першому акті \(act1SceneCount) сцен")
// Надрукує "У першому акті 5 сцен"
Аналогічно, за допомогою методу hasSuffix(_:) можна підрахувати кількість сцен, що відбувається поблизу палацу Капулетті (“Capulet’s mansion”) та келії брата Лоренцо (Friar Lawrence’s cell):
var mansionCount = 0
var cellCount = 0
for scene in romeoAndJuliet {
if scene.hasSuffix("Capulet's mansion") {
mansionCount += 1
} else if scene.hasSuffix("Friar Lawrence's cell") {
cellCount += 1
}
}
print("\(mansionCount) сцен біля палацу; \(cellCount) сцени у келії")
// Prints "6 сцен біля палацу; 2 сцени у келії"
Примітка
Методи
hasPrefix(_:)таhasSuffix(_:)виконують посимвольну перевірку на канонічну еквівалентність між розширеними кластерами графем в кожному рядку, як описано в Рівність рядків та символів.
Юнікодове представлення рядків
Коли юнікодовий рядок записується в текстовий файл чи в якесь інше місце зберігання, юнікодові скаляри в цьому рядку кодуються за допомогою одної із форм кодування Юнікоду. Кожна форма кодує рядок маленькими порціями, котрі відомі як одиниці кодування. Вони включають форму кодування UTF-8 (котра кодує рядок 8-бітними одиницями кодування), форму кодування UTF-16 (котра кодує рядок 16-бітними кодовими одиницями), та форму кодування UTF-32 (котра кодує рядок 32-бітними кодовими одиницями).
Мова Swift надає кілька різних способів отримати юнікодові представлення рядка. Можна ітерувати рядок за допомогою інструкції for-in, отримуючи окремі значення Character як юнікодові розширені кластери графем. Цей процес описано у підрозділі Робота із символами.
Іншим способом є доступ до трьох інших представлень рядка String:
- колекція одиниць кодування UTF-8 (за допомогою властивості рядка
utf8) - колекція одиниць кодування UTF-16 (за допомогою властивості рядка
utf16) - колекція 21-бітних юнікодових скалярів, еквівалентних формі кодування UTF-32 (за допомогою властивості рядка
unicodeScalars)
Кожен приклад нижче демонструє різні представлення наступного рядка, що складається із символів D, o, g, ‼ (DOUBLE EXCLAMATION MARK, або юнікодовий скаляр U+203C) та символу 🐶(DOG FACE, або юнікодовий скаляр U+1F436):
let dogString = "Dog‼🐶"
Представлення в UTF-8
Отримаємо представлення в UTF-8 рядка String ітеруючи його властивість utf8. Ця властивість має тип String.UTF8View, котрий є колекцією беззнакових 8-бітних значень (UInt8), по одному на кожен байт у представлення в UTF-8:
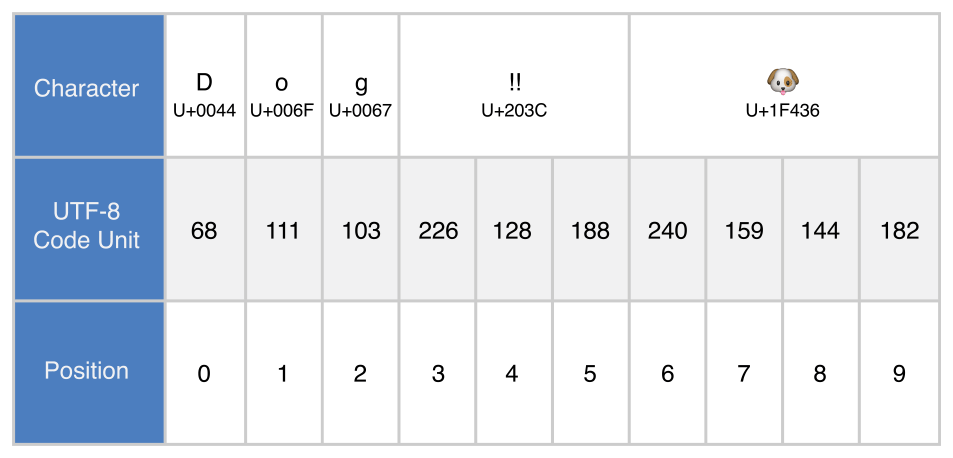
for codeUnit in dogString.utf8 {
print("\(codeUnit) ", terminator: "")
}
print("")
// Надрукує "68 111 103 226 128 188 240 159 144 182 "
У прикладі вище, перші три десяткові значення codeUnit (68, 111, 103) представляють символи D, o, та g, чиє представлення в UTF-8 збігається із їх представленням у кодуванні ASCII. Наступні три десяткові значення codeUnit (226, 128, 188) є трьох байтовим представленням в UTF-8 символу DOUBLE EXCLAMATION MARK. Останні чотири значення codeUnit (240, 159, 144, 182) є чотирьох байтовим представленням в UTF-8 символу DOG FACE.
Представлення в UTF-16
Отримаємо представлення в UTF-16 рядка String ітеруючи його властивість utf16. Ця властивість має тип String.UTF16View, котрий є колекцією беззнакових 16-бітних значень (UInt16), по одному на кожну 16-бітну одиницю кодування у представленні в UTF-16:
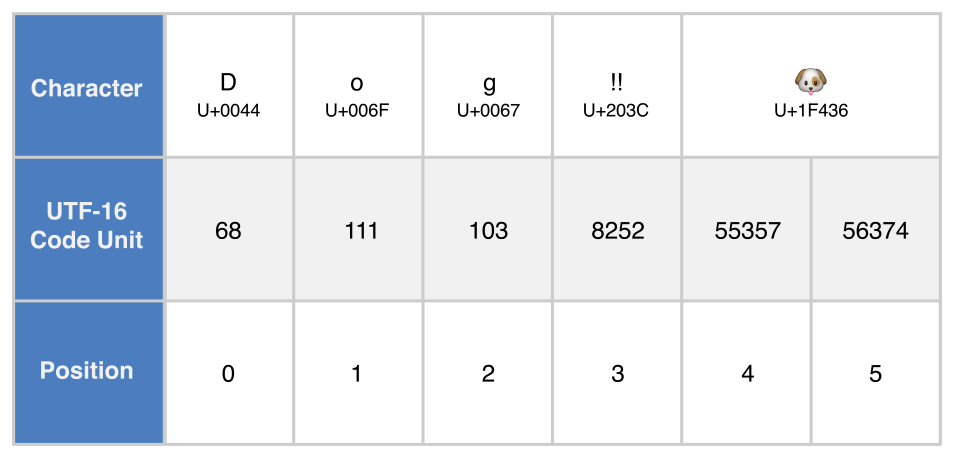
for codeUnit in dogString.utf16 {
print("\(codeUnit) ", terminator: "")
}
print("")
// Надрукує "68 111 103 8252 55357 56374 "
Знову, перші три десяткові значення codeUnit (68, 111, 103) представляють символи D, o, та g, чиє представлення в кодових одиницях UTF-16 збігається із їх представленням у кодуванні UTF-8 (бо ці юнікодові скаляри представляють символи ASCII).
Четвертим значенням codeUnit (8252) є десятковий еквівалент шістнадцяткового значення 203C, що представляє юнікодовий скаляр U+203C для символу DOUBLE EXCLAMATION MARK. Цей символ може бути представлено як єдина одиниця кодування в UTF-16.
П’яте і шосте значення codeUnit (55357 та 56374) є представленням у вигляді сурогатної пари UTF-16 символу DOG FACE. Ці значення є вищим сурогатом U+D83D (із десятковим значенням 55357) та нижчим сурогатом U+DC36 (із десятковим значенням 56374).
Представлення в юнікодових скалярах
Отримаємо представлення в юнікодових скалярах рядка String ітеруючи його властивість unicodeScalars. Ця властивість має тип UnicodeScalarView, котрий є колекцією значень типу UnicodeScalar.
Кожен екземпляр UnicodeScalar має властивість value, що повертає 21-бітне значення скаляру, представлене у значенні типу UInt32:
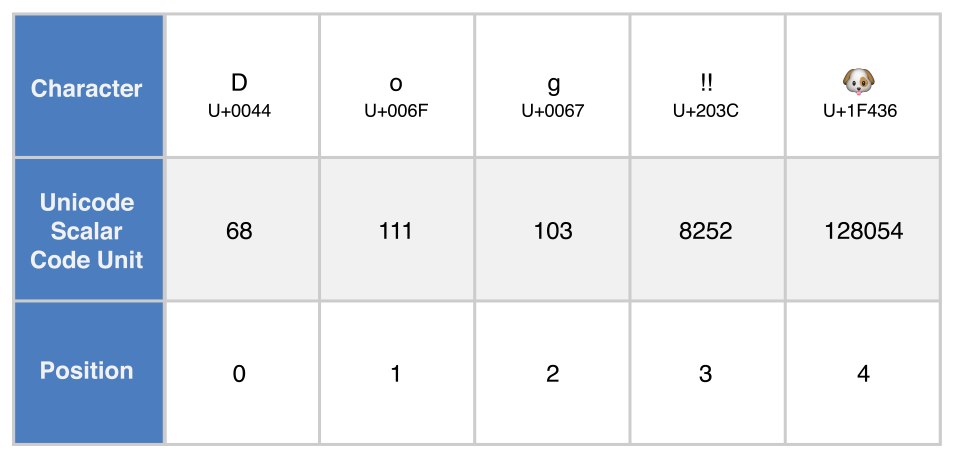

for scalar in dogString.unicodeScalars {
print("\(scalar.value) ", terminator: "")
}
print("")
// Надрукує "68 111 103 8252 128054 "
Властивості value перших трьох значень UnicodeScalar (68, 111, 103) знову представляють символи D, o, та g.
Четверте значення UnicodeScalar (8252) знову є десятковим еквівалентом шістнадцяткового значення 203C, котре представляє юнікодовий скаляр U+203C для символу DOUBLE EXCLAMATION MARK.
Значення п’ятого й останнього UnicodeScalar (128054) є десятковим еквівалентом шістнадцяткового значення 1F436, що представляє юнікодовий скаляр U+1F436 для символу DOG FACE.
Також, замість як запитувати властивості value у значень UnicodeScalar, можна використовувати ці значення для створення нових рядків, зокрема за допомогою інтерполяції рядків:
for scalar in dogString.unicodeScalars {
print("\(scalar) ")
}
// D
// o
// g
// ‼
// 🐶